垃圾快快回收了
圖像辨識 - 垃圾分類

自動辨識垃圾種類系統
垃圾快快回收了:自動辨識垃圾種類系統
FIXME: (放畫面、Github)
動機
在校園中,垃圾分類問題一直都是個大問題,垃圾集中區經常堆滿未經分類的垃圾,清潔人員為此不得不手動檢查垃圾分類,有時甚至需要逐袋檢查和分類,耗時又費力。 因此開發了一個基於人工智慧的物件偵測系統,核心技術使用 YOLO(You Only Look Once)即時物件偵測模型,該系統能自動辨別不同類型的垃圾(一般垃圾、紙類垃圾、塑膠垃圾、金屬垃圾),協助進行垃圾分類,減少人工分類的負擔,期望能改善校園清潔狀況!
模型功能
-
即時影像處理:使用攝影機實時監測畫面中是否出現垃圾,並在垃圾出現時進行垃圾分類。
-
類別偵測:能夠準確識別垃圾類型,例如一般垃圾與可回收物,為分類提供依據。
YOLO 介紹
YOLO 是一種基於深度學習的即時物件偵測模型,其特性在於僅需對圖片 進行一次 CNN(卷積神經網路)運算,就能同時完成物體的分類與位置偵測。 與傳統物件偵測模型相比,YOLO 將物體偵測的效率大幅提升,特別適合需要 高效即時處理的應用場景。 YOLO 的核心理念在於將整張圖片視為一個整體,將其劃分為多個網格, 每個網格負責檢測範圍內是否包含物體。如果有物體,模型會預測該物體的邊界框(Bounding Box)以及所屬類別和信心度。另外,YOLO 結合卷積層和全連 接層,通過一次 CNN 運算提取圖片特徵,最終輸出包含多個預測邊界框、類 別及其概率的結果張量。相比於 R-CNN 等需要多階段處理的模型,YOLO 以其 端到端(End-to-End)的架構簡化了處理流程,顯著提升了運算速度。 YOLO 的損失函數同時評估邊界框位置的準確性、信心度的合理性以及分 類結果的精確性。透過這種設計,模型在保證即時性的同時,盡可能兼顧偵測 的精確度。隨著 YOLO 的版本不斷更新,其性能也持續提升。
資料集
-
Kaggle – 資料集來源 https://www.kaggle.com/
本專案從 Kaggle 上下載上百張垃圾影像的資料集,該資料集已按類別(塑膠、紙類、金屬等)進行基本分類,而有些以進行標註,可直接用於模型的訓練和驗 證。
-
Roboflow – 標註工具 https://roboflow.com/
為了進一步整理和標記影像資料,使用了 Roboflow 來進行圖像標註。

訓練過程
-
訓練環境
- 作業系統:Windows 11
- Python 版本:3.9
- 深度學習框架:PyTorch
- GPU 支援:NVIDIA RTX 4050(訓練主要在 GPU上進行以提升速度)。
-
資料集準備
確保資料集按照 YOLO 格式結構化,並產生 data.yaml 配置文件,其中包括:
- train:訓練資料集的路徑。
- val:驗證資料集的路徑。
- test:測試資料集的路徑。
- nc:垃圾分類的類別數量(一般垃圾、紙類、塑膠、金屬,總共 4 類)。
- names:垃圾類別名稱([‘general’, ‘paper’, ‘plastic’,‘metal’])。
訓練結果
 在訓練完成後,將訓練得到的 YOLOv10 模型應用於即時影像的垃圾
分類辨識。結果顯示,模型能夠有效地進行物件檢測並標註垃圾類別。模型為不同類型的垃圾賦予不同顏色的邊框,紫色框為一般垃圾,紅色框為紙類,粉色框為塑膠,橘色框為金屬垃圾。這些框有標示出圖像中的物品並指出其對應的分類,儘管模型的表現整體良好,但仍存在一些誤判情況。有時模型有時會錯誤地將背景中的物體誤標為垃圾類別,有時會將人誤判為金屬垃圾。
在訓練完成後,將訓練得到的 YOLOv10 模型應用於即時影像的垃圾
分類辨識。結果顯示,模型能夠有效地進行物件檢測並標註垃圾類別。模型為不同類型的垃圾賦予不同顏色的邊框,紫色框為一般垃圾,紅色框為紙類,粉色框為塑膠,橘色框為金屬垃圾。這些框有標示出圖像中的物品並指出其對應的分類,儘管模型的表現整體良好,但仍存在一些誤判情況。有時模型有時會錯誤地將背景中的物體誤標為垃圾類別,有時會將人誤判為金屬垃圾。
訓練結果圖表
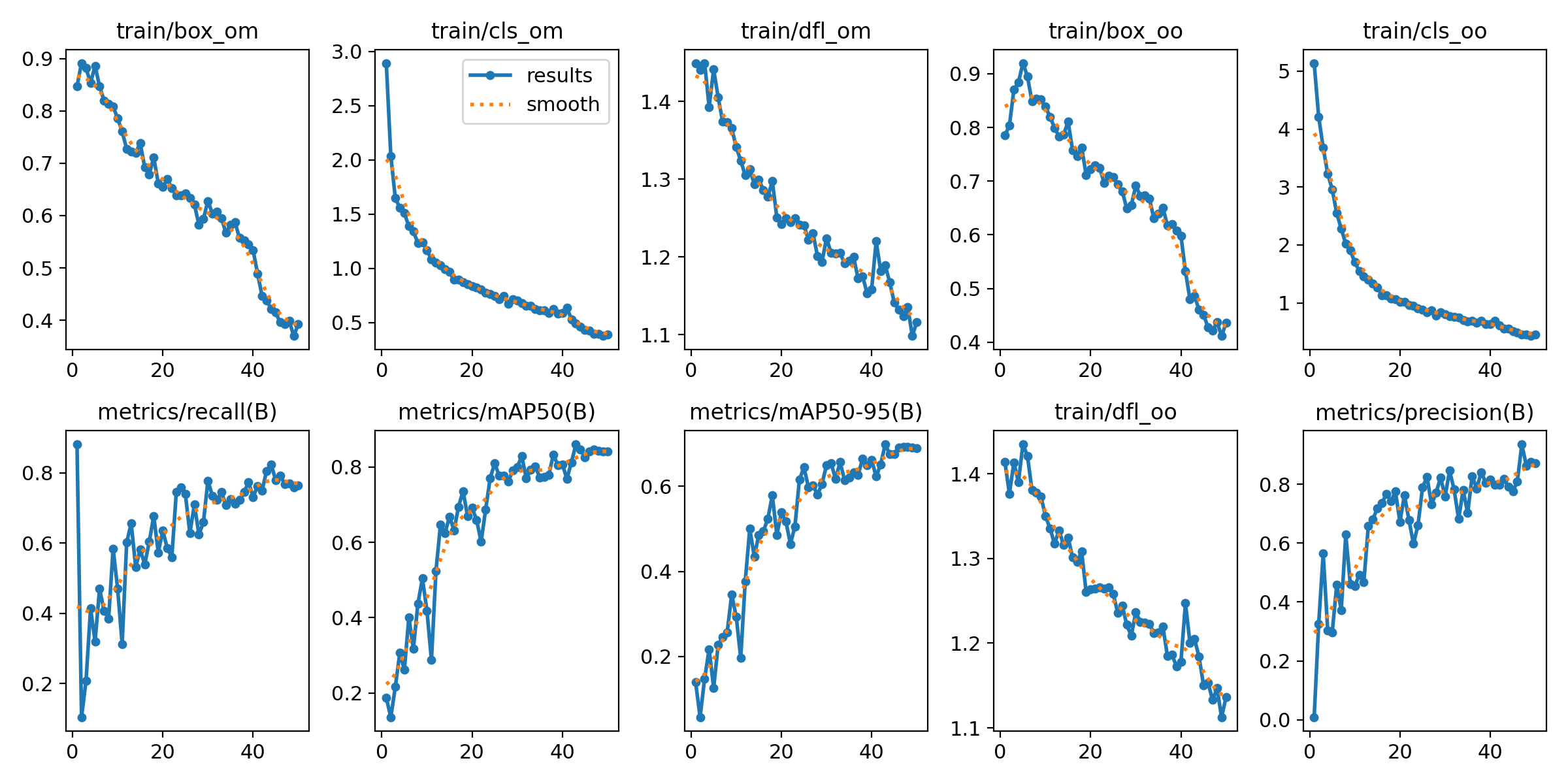
-
損失函數趨勢
上排的圖表由左至右分別展示了 One-to-Many Head 的邊界框回歸損失(train/box_om)、分類損失(train/cls_om)及分佈式焦點損失(train/dfl_om)。而 One-to-One Head 的損失函數趨勢則以 train/box_oo、train/cls_oo 和 train/dfl_oo 進行呈現。
- Bounding Box 損失 (train/box_om):此指標反映模型對目標邊界框的預測準確度。隨著訓練進行,損失值從約 0.9 逐漸下降至 0.4,顯示模型對物件判斷能力逐漸增加。
- 分類損失 (train/cls_om):此指標衡量模型對物件類別的預測準確度。從初始的 3.0 降至約 0.5,表明模型在垃圾分類方面有顯著進步。
- 分佈式焦點損失 (train/dfl_om):DFL 是一種用於目標偵測的損失函數,用於提高預測的信心度。圖表中可看出,數值從約 1.4 降至 1.1,表明模型在邊界框分佈上的學習效果良好。
損失函數的整體下降趨勢顯示模型收斂穩定,未發現過擬合跡象。
-
性能指標變化
下排圖表則是訓練過程中的性能指標。
- 召回率 (Recall):召回率指的是事實為正樣本中有幾個是預測正確的。苦從圖表看出,召回率數值由最初的 0.2 增加至 0.8,顯示模型能捕捉到更多的正確目標。
- 精確率 (Precision):精確率為模型預測為正樣本時的準確程度。圖中顯示模型精確率數值從約 0.3 提升至約 0.8,說明模型對正確檢測結果的信心不斷提高。
- 平均精度 (mAP):
- mAP@50 在訓練結束時達到 0.8,表明模型在 IoU 阈值為 0.5 時具有較高的檢測準確度。
- mAP@50-95 則逐步上升至 0.6,展示了模型在多個 IoU 阈值下的整體穩定性。
混淆矩陣
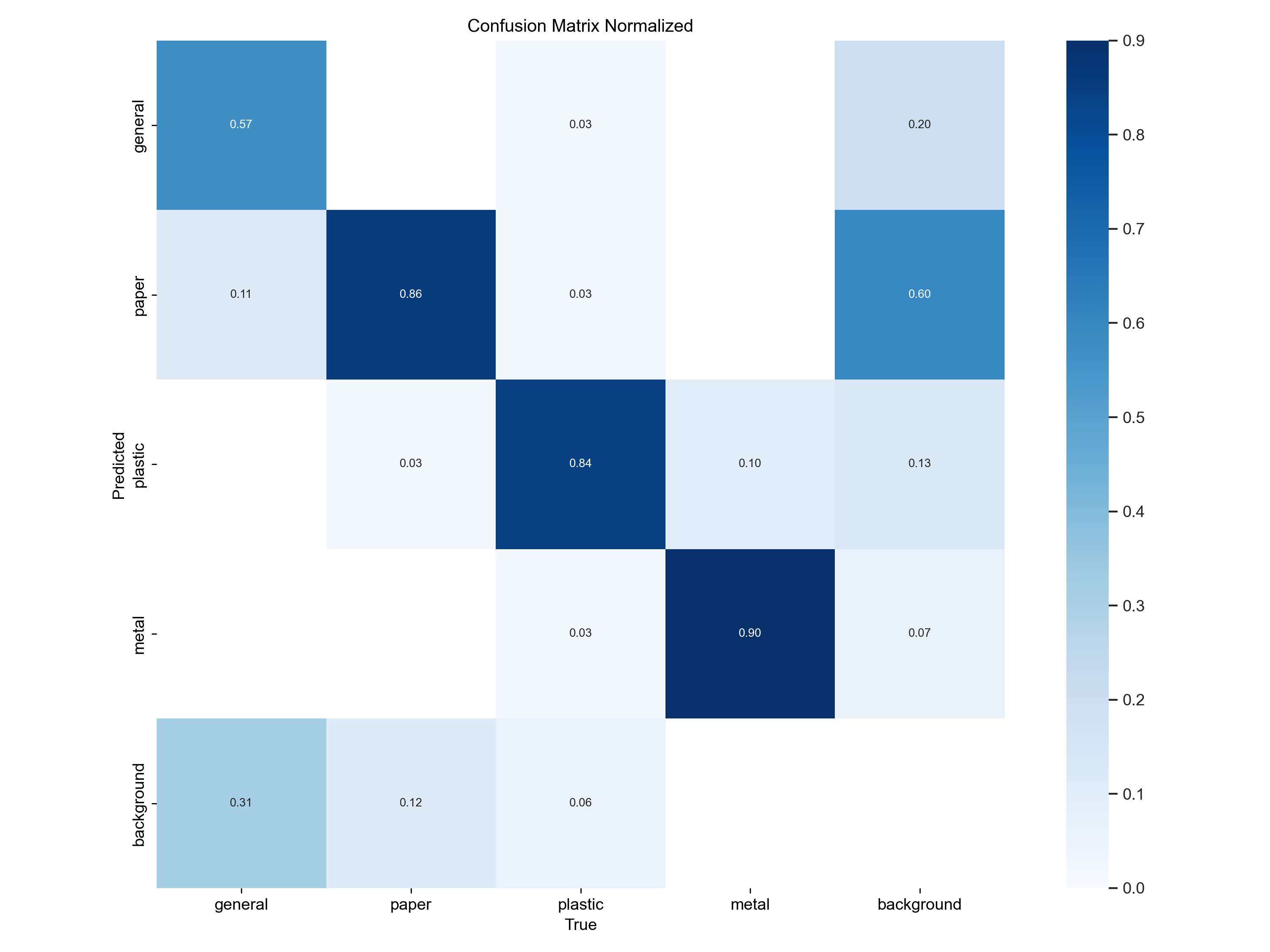
- 準確分類:
- 可看出金屬物件的分類準確率最高,達到 90%,顯示該類數據特徵鮮明,模型辨識效果良好。
- 紙類與塑膠的分類準確率分別為 86% 和 84%,說明模型對這些類別的識別能力較為穩定。
- 誤分類:
- 背景的誤分類問題較為明顯,部分背景被誤判為金屬或其他類別,可能是因為背景特徵與某些物件的相似性造成。
- 紙類與塑膠之間有些混淆,可能與其材質或形狀相似有關。
總結
從模型在垃圾分類中的訓練結果可看出其能有效區分一般垃圾、紙 類、塑膠、金屬四種類別,準確度高達 86%。雖然有些誤判,但大多時間還是能分類初垃圾種類。未來研究可以針對誤分類問題進行優化,例如採用更多的背景資料進行訓練,或利用自動化標註工具提高數據質量,來進一步提升模型的應用。
-
全民健保
-
BobyGame
-
垃圾快快回收了
-
Food Pangolin
Related: